第13章 LangChain框架概述与基础组件
学习目标
- 理解LangChain框架的核心概念与设计理念
- 掌握LangChain的主要组件和功能模块
- 了解如何使用LangChain构建AI应用工作流
- 学习LangChain与搜索、向量数据库的集成方式
什么是LangChain?
LangChain是一个专为大型语言模型(LLM)应用开发设计的框架,它提供了一系列组件和工具,帮助开发者轻松构建基于LLM的复杂应用。
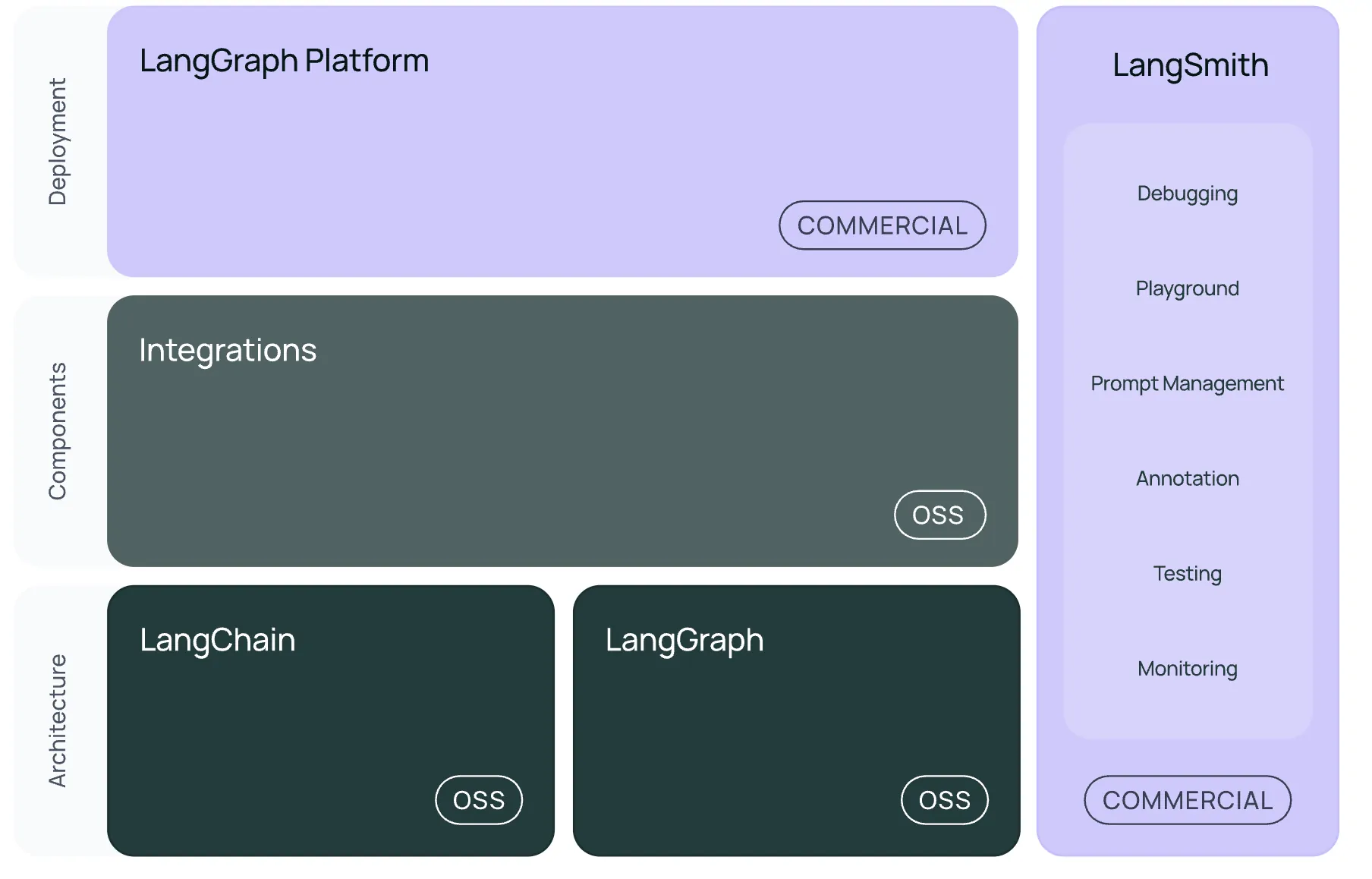
LangChain的核心价值在于:
- 组件化设计:提供模块化组件,便于灵活组合和定制
- 工作流编排:允许开发者设计复杂的多步骤AI工作流
- 集成生态:内置与众多第三方服务和工具的集成接口
- 抽象接口:为LLM、向量存储、检索等提供统一抽象层
- 开箱即用:提供丰富的预设模板和工具链
LangChain的核心组件
LangChain的架构由以下几个核心组件构成:
1. 模型 (Models)
模型组件负责与各种AI模型进行交互,主要包括:
- LLMs:管理对大语言模型的调用,支持OpenAI、DeepSeek、Anthropic等
- Chat Models:专门针对对话式AI的接口
- Text Embedding Models:用于生成文本的向量表示
python
from langchain_openai import ChatOpenAI
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
API_KEY = os.getenv("API_KEY")
# 初始化Chat模型(用于DeepSeek)
chat_model = ChatOpenAI(
model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com/v1"
)
# 完整的chatCompletion示例
from langchain_core.messages import HumanMessage, SystemMessage
# 设置系统信息和用户信息
messages = [
SystemMessage(content="你是一个专业的AI助手,擅长回答技术问题。"),
HumanMessage(content="请解释一下DeepSeek-Coder模型的主要特点。")
]
# 发送消息并获取回复
response = chat_model.invoke(messages)
print(response.content)
# 还可以使用链式API
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的AI助手,擅长回答技术问题。"),
("human", "{question}")
])
chain = prompt | chat_model
result = chain.invoke({"question": "请解释一下DeepSeek-Coder模型的主要特点。"})
print(result.content)2. 提示词 (Prompts)
提示词组件用于构建和管理发送给模型的提示,包括:
- PromptTemplates:提示词模板,支持变量插入
- Example Selectors:动态选择少样本学习示例
- Output Parsers:解析模型输出为结构化数据
python
from langchain_core.prompts import PromptTemplate
# 创建提示词模板
prompt_template = PromptTemplate(
input_variables=["query", "context"],
template="根据以下上下文回答问题:\n\n上下文: {context}\n\n问题: {query}\n\n回答:"
)
# 填充模板
prompt = prompt_template.format(
query="DeepSeek有哪些主要特点?",
context="DeepSeek是一个先进的大语言模型,具有强大的理解能力和多语言支持。"
)3. 内存 (Memory)
内存组件用于管理对话历史和状态,包括:
- ConversationBufferMemory:简单的对话历史缓存
- ConversationSummaryMemory:对话摘要记忆
- VectorStoreMemory:基于向量数据库的记忆
python
from langchain_core.memory import ConversationBufferMemory
# 创建对话记忆
memory = ConversationBufferMemory()
# 添加对话
memory.chat_memory.add_user_message("你好,DeepSeek!")
memory.chat_memory.add_ai_message("你好!我是DeepSeek AI助手,有什么可以帮助你的吗?")
# 获取对话历史
print(memory.load_memory_variables({}))4. 链 (Chains)
链组件用于组合多个步骤成为工作流,包括:
- 基础链:使用LangChain表达式语言(LCEL)构建链
- RunnableSequence:用于构建复杂的多步骤链
- RunnableBranch:根据输入动态选择执行路径
python
# 使用LangChain表达式语言(LCEL)构建链
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
# 创建提示模板
template = """回答以下问题:
问题: {question}
"""
prompt = PromptTemplate(template=template, input_variables=["question"])
# 构建完整链 - LCEL 方式
chain = prompt | chat_model | StrOutputParser()
# 执行链
response = chain.invoke({"question": "DeepSeek AI有哪些主要功能?"})
print(response)
# 复杂链示例 - 包含条件处理
from langchain_core.runnables import RunnableBranch, RunnablePassthrough
# 条件分支处理
def is_technical_question(input_data):
return "技术" in input_data["question"] or "代码" in input_data["question"]
technical_prompt = ChatPromptTemplate.from_messages([
("system", "你是一位技术专家,擅长解答技术问题。"),
("human", "{question}")
])
general_prompt = ChatPromptTemplate.from_messages([
("system", "你是一位通用知识专家,擅长解答各类常见问题。"),
("human", "{question}")
])
# 创建条件分支链
branch_chain = RunnableBranch(
(is_technical_question, technical_prompt | chat_model | StrOutputParser()),
general_prompt | chat_model | StrOutputParser()
)
# 执行条件分支链
technical_response = branch_chain.invoke({"question": "解释一下DeepSeek中的技术架构"})
general_response = branch_chain.invoke({"question": "DeepSeek是什么?"})5. 工具与检索 (Tools & Retrievers)
工具组件提供了各种功能扩展和资源检索能力:
- Tools:集成各种外部工具和API
- Retrievers:从各种数据源检索相关信息
- Document Loaders:加载和处理不同格式的文档
python
from langchain_community.tools import DuckDuckGoSearchRun
from langchain_community.retrievers import WikipediaRetriever
from langchain_core.tools import tool
# 初始化搜索工具
search_tool = DuckDuckGoSearchRun()
# 使用搜索工具
search_result = search_tool.invoke("DeepSeek AI最新进展")
# 初始化维基百科检索器
wiki_retriever = WikipediaRetriever()
# 检索相关文档
wiki_docs = wiki_retriever.get_relevant_documents("大语言模型")
# 创建自定义工具
@tool
def calculate(expression: str) -> str:
"""计算数学表达式"""
try:
return str(eval(expression))
except Exception as e:
return f"计算出错: {str(e)}"6. 代理 (Agents)
代理组件允许模型根据任务动态选择工具,实现自主决策:
- Agent:实现模型驱动的工具选择和执行
- AgentExecutor:管理代理的执行流程
- Tool:定义代理可以使用的工具
python
from langchain.agents import AgentExecutor, create_react_agent
from langchain_core.tools import Tool
from langchain_core.prompts import ChatPromptTemplate
# 定义工具
tools = [
Tool(
name="搜索",
func=search_tool.invoke,
description="当你需要搜索网络信息时使用"
),
Tool(
name="维基百科",
func=wiki_retriever.get_relevant_documents,
description="当你需要查找百科知识时使用"
),
calculate
]
# 创建代理提示模板
agent_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个智能助手,可以利用工具帮助用户解决问题。"),
("human", "{input}")
])
# 创建代理
agent = create_react_agent(chat_model, tools, agent_prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 执行代理
result = agent_executor.invoke({"input": "DeepSeek AI是什么,它有哪些主要竞争对手?"})
print(result["output"])LangChain的工作流范式
LangChain提供了多种构建应用的工作流范式:
1. 基于链的工作流
最简单的工作流方式,通过组合各种链来处理特定任务:
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# 创建两个独立的提示模板
first_prompt = ChatPromptTemplate.from_messages([
("system", "你是一位AI应用领域专家。"),
("human", "简要介绍{topic}的基本概念")
])
second_prompt = ChatPromptTemplate.from_messages([
("system", "你是一位教育领域专家,擅长分析新技术在教育中的应用。"),
("human", "基于以下内容,详细分析在教育领域的具体应用案例:\n\n{context}")
])
# 构建顺序工作流
def process_first_response(input_data):
return {"context": input_data}
chain = (
first_prompt
| chat_model
| StrOutputParser()
| process_first_response
| second_prompt
| chat_model
| StrOutputParser()
)
# 执行工作流
result = chain.invoke({"topic": "人工智能在教育领域的应用"})
print(result)2. 基于代理的工作流
更灵活的工作流方式,由LLM自主决定使用什么工具和执行顺序:
python
from langchain.agents import AgentExecutor, create_react_agent
from langchain_core.tools import tool
from langchain_core.prompts import ChatPromptTemplate
# 自定义工具
@tool
def calculate(expression: str) -> str:
"""计算数学表达式"""
try:
return str(eval(expression))
except:
return "无法计算该表达式"
@tool
def search_internet(query: str) -> str:
"""搜索互联网获取信息"""
return search_tool.invoke(query)
# 创建代理提示模板
agent_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个智能助手,可以利用工具帮助用户解决问题。需要时使用工具,但不要过度使用。"),
("human", "{input}")
])
# 创建代理
agent = create_react_agent(chat_model, [calculate, search_internet], agent_prompt)
agent_executor = AgentExecutor(agent=agent, tools=[calculate, search_internet], verbose=True)
# 执行代理
result = agent_executor.invoke({"input": "计算23*45,并查找这个数字在数学中有什么特殊含义"})
print(result["output"])3. 基于检索增强生成 (RAG) 的工作流
结合检索和生成的工作流,用于处理基于知识库的问答:
python
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# 示例:创建向量数据库
# 准备文档
loader = TextLoader("path/to/document.txt")
documents = loader.load()
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
splits = text_splitter.split_documents(documents)
# 创建嵌入和向量存储
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# 创建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
# 创建RAG提示模板
template = """根据以下检索到的上下文信息回答用户问题。
如果上下文中没有相关信息,请直接说明无法回答,不要编造信息。
上下文:
{context}
问题: {question}
"""
rag_prompt = ChatPromptTemplate.from_template(template)
# 构建RAG链
def format_docs(docs):
return "\n\n".join([d.page_content for d in docs])
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| chat_model
| StrOutputParser()
)
# 执行RAG链
answer = rag_chain.invoke("人工智能的伦理问题有哪些?")
print(answer)选型建议
项目规模与复杂度:
- 小规模 PoC/脚本:直接使用官方 SDK(OpenAI/HF)或 LMQL;
- 中等复杂度 RAG:Haystack、LlamaIndex;
- 多 Agent 协同 / 企业级:AutoGen + Semantic Kernel;
- 快速原型 / 可视化:Flowise、n8n。
可维护性与团队技能:
- 若团队熟悉 Python,推荐轻量 Python SDK(Griptape、Haystack);
- 若需要跨语言(C#、Java)或企业级监控,Semantic Kernel 更合适;
- 对前端/低代码团队,Flowise、Langflow、n8n 可降低门槛。
生态与社区:
- Haystack、Hugging Face Transformers、Semantic Kernel 社区活跃、文档完善;
- 新兴项目如 SuperAGI、Langroid 等活跃度待观察。
LangChain与DeepSeek的集成
LangChain提供了与DeepSeek API的集成支持,通过OpenAI兼容接口实现:
python
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
API_KEY = os.getenv("API_KEY")
# 初始化DeepSeek聊天模型
deepseek_chat = ChatOpenAI(
model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com/v1"
)
# 使用DeepSeek模型进行对话
messages = [
SystemMessage(content="你是DeepSeek AI助手,一个专业、友好的AI助手。"),
HumanMessage(content="解释量子计算的基本原理")
]
response = deepseek_chat.invoke(messages)
print(response.content)
# 使用链式API
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你是DeepSeek AI助手,一个专业、友好的AI助手。"),
("human", "{input}")
])
chain = prompt | deepseek_chat
result = chain.invoke({"input": "量子纠缠是什么?"})
print(result.content)思考题
- LangChain的组件化设计有什么优势?它如何简化AI应用的开发过程?
- 如何使用LangChain实现一个能够搜索互联网并回答问题的聊天机器人?
- 比较基于链和基于代理的工作流方式,它们各自适合什么场景?
- 你能想到哪些创新的方式来使用LangChain的记忆组件增强用户体验?
接下来,我们将深入探讨如何使用LangChain实现搜索功能的集成,打造强大的信息获取工作流。